
The Widow is a Stranger Encounter in Red Dead Redemption 2. This Walkthrough shows how to complete the Stranger Missions.
Quest Giver: Charlotte Balfour
Region: Willard’s Rest, north-eastern-most corner
Requirements: being in Chapter 5 or 6
Reward: $ 125
The Widow Starting Location
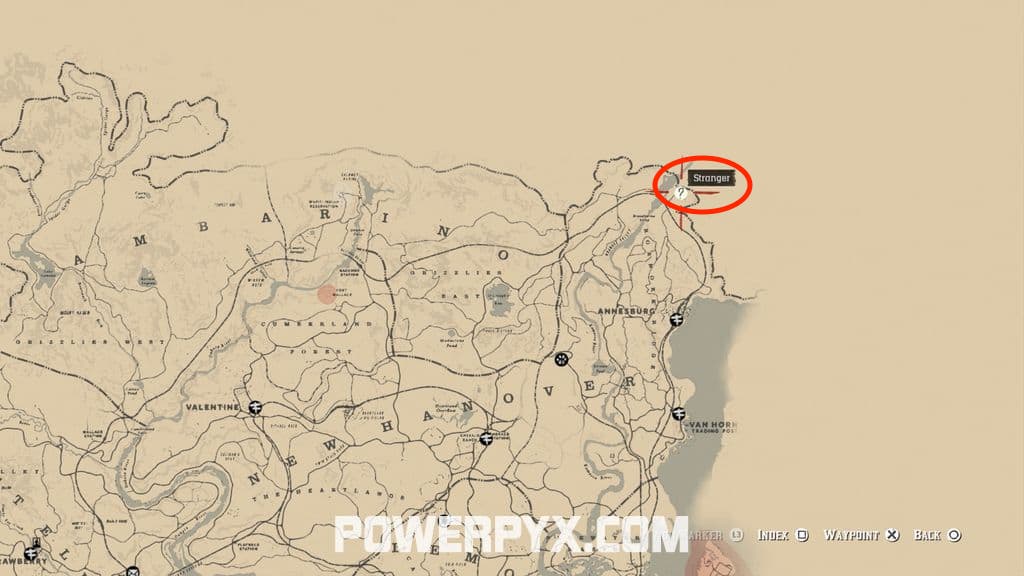
In Chapters 5 and 6, Arthur can meet a woman north of Annesburg, who is sitting at a grave. She lost her husband and seems very desperate. Arthur offers her a lift to town, but she turns it down. However, she agrees to Arthur’s invitation to show her how to hunt and thus provide for herself.
 |
 |
 |
 |
Walk a bit to the south, to the marked area on the map. The widow by the name of Charlotte should learn how to track and skin a rabbit, Arthur will do the killing this time.
If she doesn’t find one, use your Eagle Eye  +
+  to track any animal and approach. This way, “she will find” it, too.
to track any animal and approach. This way, “she will find” it, too.
Shoot the rabbit and let her do the skinning.
Time to head home now.
 |
 |
 |
 |
On the way back, we will be attacked by two wolves coming from the hill on the right side. Use Dead Eye to take out the threat.
Charlotte, who fleed, will pick up the rabbit again and you can finally head the last bit to her home.
She is very thankful and invites you to check on her sometime again.
 |
 |
 |
 |
Part II

A few days after the first encounter, we can visit Charlotte again.
This time, we can literally hear her from a distance, as she is trying to use a rifle.
She is clearly lacking skill, as she hasn’t hit a single bottle she set up. Arthur gives her a few tips and shows how it’s done.
At one point, a rat is walking close to the bottles and Charlotte asks us to get rid of it, because it bothered her for days.
Eventually, she will hit a bottle and is pleased with her progress.
 |
 |
 |
 |
 |
 |
She invites us in to have something to eat – from the rabbit we killed the other day. While eating, the screen will fade a bit a few times, because Arthur’s disease is giving him a hard time.
When trying to leave, Arthur passes out on the floor and wakes up in bed sometime later.
Charlotte has left a letter for us, asking to take the money from her nightstand, as she won’t need it. She is thankful that we showed her how to survive for herself.
 |
 |
 |
 |
 |
 |
Part III

A few days later we can check on Charlotte a final time. This time she is dressed up quite nicely, thanks us yet another time and says we might take anything we want from her house.
 |
 |
 |
 |
 |
 |
This concludes the “The Widow of Willard’s Rest” Stranger Encounter in Red Dead Redemption 2 (RDR2). For all other Stranger Missions check out the full Red Dead Redemption 2 Stranger Missions Walkthrough.
Ryan says
[REDACTED]
SPOILERS.
If you only complete the first mission and don’t finish the remaining ones by the end of Chapter 6, she will be dead in her cabin in the Epilogue. So this stranger mission can be missable.
Dave says
I was wondering if that would be the case
Mozart says
I did all of the missions in the epilogue. Part 1, 2 and 3.
ian says
yeah, I came back as john and she was dead asf
T-ric says
She ran in the Woods and did not come back after I killed the wolves. So I searched for her and found the Cannibals of the Murfy Gang and in the Camp of those hillbilly basterds i found a corpse of a Woman with black hair, a blue blouse and a brown skirt. And Charlotte was not at the house afterwards…..
Hunter says
She was alive for and said any friend of aurthers is a friend if mine
hunter says
4 parts to this in case u didnt know
Dave says
You can go back in the epilogue and have a conversation with her if you complete the full mission line
Kat says
My mission disappeared. After killing the wolves she fled and ran in circles and the mission was just cancelled somehow. It never showed up again and now she’s dead…
Chris says
Same happened to me. She ran from me like I was assaulting her even though I only killed the wolves.
Arthur Morgan says
I tried to smash her like an avocado but she rejected me 🙁
Geronimo Williams says
This mission is a nod to Vardis Fisher’s book Mountain Man which was the source material for the Robert Redford film adaptation Jeremiah Johnson. In the book there is an identical character that the protagonist looks after.
Reedybea5t says
It’s not there for me
PowerPyx says
You must reach Chapter 6 for it to show up.
Vickie says
I did it as John but she didn’t invite me in and I can’t finish the quest. Any suggestions?
Arthur Morgan says
So does she disappear from the game after the meeting with John?
I went back a few days later and she’s nowhere to be found. Plus her doors are now locked.
Does she disappear for good or does she return after a while?
Hunter says
There for me and I saw her as aurthers, and *o**
ziggurcat says
finished part 2, waited a few days, and no more mission, no icon. door to the house is unlocked, and no one is in there.
Yellowsnow says
Did anyone run into the guy at his camp site, on the hill just below Osman Grove between the dear and wolf symbols? He was talking about a widow he found up north, and she asked him to leave. He watched her from the bushes. I ended up killing him, does anyone know if that will affect this mission?
Mia says
Yeah I killed a guy at his camp who was talking the same things. In his tent he had paintings of naked women.
Dr No says
I thought he was talking about Sadie so I killed him
Lars-Erik Østerud says
What if you finish the first two missions as Arthur? Will she still die if the 3rd is not done before Arthur dies? Are there any other missions that can “get broken” if done halfway when Arthur dies?
Tim says
She told me “you have a strange choice of hat” in the third mission because i was wearing the viking helmet
Aymen says
Ok
Josh says
First play through I never encountered Charlotte as Arthur…but later, as John completed her storyline, parts 1,2, and 3; however she doesn’t invite John in for dinner…presumably because it’s scripted for Arthur to have his coughing fit and collapse during the scene. Second play through I met her as Arthur and completed the entire strand. Not too long after I, too, encountered the creep south of Osman Grove: hogtied his sick ass and threw him in the fire. The hell if he was goin’ anywhere near her; dude was a hardcore perv, what with all those nude photos he had strung up inside his tent.
Checo says
Never would have tought that this side storyline would have so many different endings. I just finished started the third part, came here to search if there was any more to add to it since ive been invited into her house. I was hoping she was maybe hiding something or more happened but i guess thats not it. Just a goodbye? Please comment if you found something else.
W says
It has…TWO endings…thats not a lot
hunter says
There are 3 parts as arthur.
In epilogue as John there is a part 4.
The part 4 only works if u see her as arthur 3rd time(when she’s dressed up). John tells her a unique story
William says
I remember playing the game…not knowing how it would end…thinking a nice ending would have been a remarkable cure for Arthur, with Charlotte and he riding off into the sunset, living happily ever after. Oh, the horror. Actually, Rockstar could probably make a mint selling some creative ‘alternate endings DLC’. I’m in!
William says
Ha! This reminded me of when Walter White died.
Ray says
She had droopy knockers
Riansyah Jr. says
part III does not exist
Jim Slade says
I strangled her to death after completing the missions. When I looted her corpse she had some sort of amulet on her that fulfilled an item request, which seemed odd. Maybe I’ll try going back to before I killed her, hogtie her and drop her off gift wrapped to the pervert in the camp South now that I’ve learned about him.
Joe says
Damn, that’s harsh. But I will be trying that later. Haha
Zeek Liviu says
What happens if I scary her during the second encounter? Will I never meet her again? 🙁
Jessica says
I met her, killed the rabbit, killed the wolves turned around for one moment only to hear a cougar turned back and a cougar killed her. I was speechless.
Captain Jarak Panther says
On my first play through, I completed all three parts to this mission, but during the epilogue, or post epilogue, her icon showed up on my map again & I had a pleasant encounter with her as John Marsten. She said “Any friend of Arthur’s is a friend of mine.” Her icon never showed up after that.
Anthony C says
Same deal with me. The house is locked down. I even shot out one of the windows and tried diving inside. I was disappointed because I was expecting to go back and find free loot. I figured she moved back to where she came from.
I hope that creep didn’t have anything to do with her disappearance. The thought of it just makes me sad. :/
Elijahhhhh says
Finish quests as arther then go back as john
KingofFluff says
The whole mission is missing in my journal is that on purpose